

Photo by Google DeepMind on Unsplash
You've heard of Keras before, what is it?
A brief overview of what Keras is and how it's used to build machine learning models.


Keras is an API (Application Programming Interface) used in machine learning for building deep learning models with Python. It uses TensorFlow under the hood to make building models simpler and faster.
Building a model
Model foundation
Keras has a couple of pre-made classes and functions to instantiate a model which makes up part of the sequential aspect of the API. For example, tf.keras.Sequential sets up a foundation to start stacking layers to model a neural network.
model = tf.keras.Sequential()
As brilliantly illustrated in the cover image above, it uses the idea of layers to represent sections of a neural network, these are categorised in the following ways.
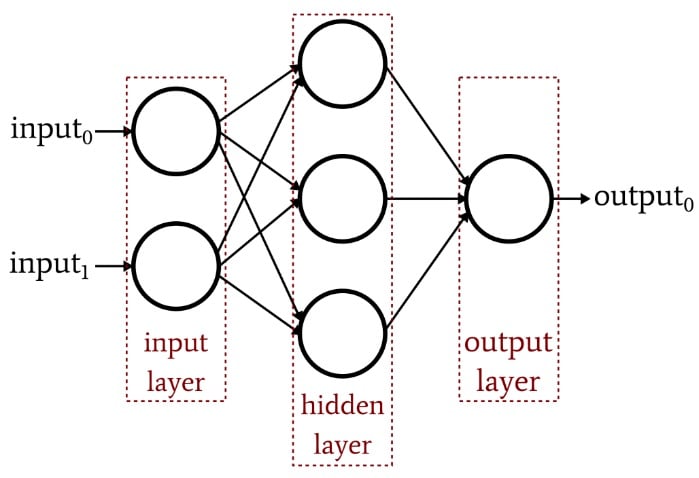
Input layer
The input layer is where any required processing of the input data is done such as image transformation or text embedding. The basic one is tf.keras.layers.Flatten.
input_layer = tf.keras.layers.Flatten(
data_format=None, **kwargs
)
model.add(input_layer)
Hidden layers
This is followed by any number of hidden layers, these do most of the heavy lifting using mathematical activation functions to determine the eventual prediction of the model.
You can tweak the complexity of a model by including as many of these layers as needed as well as specifying the number of units as a parameter for each layer, this corresponds to its quantity of nodes. The one I've seen used the most is tf.keras.layers.Dense.
hidden_layer = tf.keras.layers.Dense(
units, activation=None, use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None,
activity_regularizer=None, kernel_constraint=None, bias_constraint=None,
**kwargs
)
model.add(hidden_layer)
Output layer
Finally ending with the output layer, where the output of all the previous activation functions in the hidden layers is used to make the final prediction of the model. This also tends to use the Dense layer method by specifying the shape of the prediction as a value in the units parameter, i.e. 3 for something like rock, paper and scissors ([x, y, z]) or 2 for heads/tails.
output_layer = tf.keras.layers.Dense(3)
model.add(output_layer)
Configuration
Once the layers are built, the model is then "compiled" with tf.keras.Model.compile but not in the typical meaning you'd expect, it's more like appending configuration.
model.compile(
optimizer, loss=None, metrics=None, loss_weights=None,
sample_weight_mode=None, weighted_metrics=None, **kwargs
)
The main arguments that this method takes which are worth noting are:
optimizer- An optimiser function which determines how the model is trainedloss- A loss function which is passed into the optimiser and used as an indicator and aimed to be minimisedmetrics- An array of metrics to be calculated and used to monitor training e.g. accuracy
Time to train!

Once the model is built and configured, training can finally begin withtf.keras.Model.fit.
model.fit(
x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None,
validation_split=0.0, validation_data=None, shuffle=True, class_weight=None,
sample_weight=None, initial_epoch=0, steps_per_epoch=None,
validation_steps=None, validation_batch_size=None, validation_freq=1,
max_queue_size=10, workers=1, use_multiprocessing=False
)
You specify the training data as x and the number of iterations as epochs as well as the batch_size. Some validation_data is also passed here to calculate the loss and metrics provided during configuration.
Evaluate
After training, you can check the effectiveness of the model with tf.keras.Model.evaluate by providing test data as x.
model.evaluate(
x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None,
callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False,
return_dict=False
)
The output would show the outcome of the loss function and any metrics you provided during configuration such as accuracy.
49/49 - 2s - loss: 0.3269 - accuracy: 0.8505
loss: 0.327
accuracy: 0.850
Overfitting and underfitting
At this point, you should be able to gauge whether the model is experiencing overfitting or underfitting.
If the model converges to a relatively low accuracy, it's underfitting. There may not be enough variety in the training data for it to handle the testing data accurately, the training data needs to be expanded to include a wider range of expected outcomes. The model may also not be sophisticated enough and may need to be improved.
Conversely, if accuracy reaches a plateau (or even decreases!) regardless of expanding the training data, it's overfitting. The model has too much training data and cannot generalise to unknown test data.
In this case, the model could be optimised to be more efficient with techniques such as regularisation. This would essentially put a limit to the model's learning, forcing it to be more efficient.
Predict
Once the model has been trained, you can give unknown data to the model (i.e. data not used to train the model) to make predictions using tf.keras.Model.predict.
model.predict(
x, batch_size=None, verbose=0, steps=None, callbacks=None, max_queue_size=10,
workers=1, use_multiprocessing=False
)